Как понять LSTM сети
Перевод статьи из блога Кристофера Олаха. Вы можете присылать ваши замечания на почту или в виде пулл-реквестов на Github.
Рекуррентные нейронные сети
Было бы неправильно сказать, что человеческий процесс мышления начинается каждую секунду с пустого места. Когда вы читаете эту статью, ваше понимание каждого следующего слова зависит от понимания предыдущего. Вы не отбрасываете предыдущий опыт, чтобы начать думать с чистого листа. Ваши мысли обладают неким постоянством.
Традиционные нейронные сети на такое не способны, и это, очевидно, серьезный изъян. К примеру, представьте, что вы хотите классифицировать, что за тип события происходит в фильме в каждый момент времени. В случае традиционных нейронных сетей, неясно, как знания о предыдущих событиях в фильме могут помочь им охарактеризовать последующие события.
Рекуррентные нейронные сети (РНС или RNNs) призванны решить именно эту проблему. Это сети с циклическими связями, позволяющие хранить информацию.

Рекуррентные нейронные сети имеют циклические связи.
В диаграмме выше участок нейронной сети \(A\) получает некие данные \(x_i\) на вход и подает на выход некоторое значение \(h_i\). Циклическая связь позволяет передавать информацию от текущего шага сети к следующему.
Эти циклы выглядят загадочно. Однако, если вдуматься, рекуррентные нейронные сети не так уж сильно отличаются от обычных нейронных сетей. Их можно представить себе как множество копий одной и той же сети, причем, каждая копия передает сообщение следующей копии. Посмотрите, что получится, если мы развернем цикл:
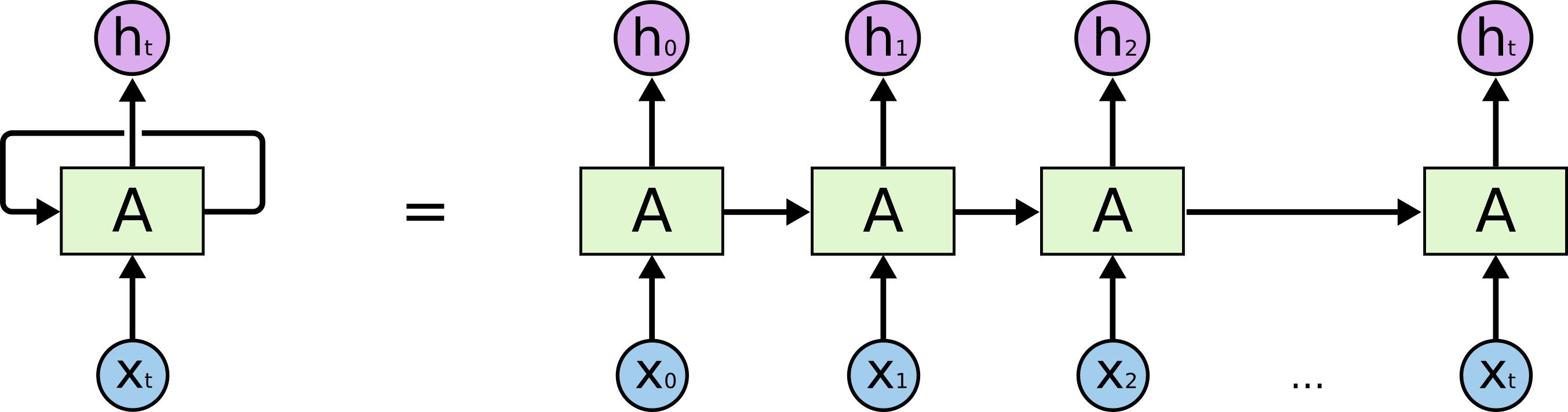
Развернутая рекуррентная нейронная сеть.
Такая “цепная” сущность показывает, что рекуррентные нейронные сети по природе своей тесно связаны с последовательностями и списками. Было бы естественно использовать такую архитектуру нейронных сетей для работы с этими типами данных.
И, конечно же, их уже используют. В последние несколько лет РНС были успешно применены для решения широкого спектра задач: распознавание речи, моделирование языка, перевод, описание изображений… Список можно продолжить. Я предоставлю обсуждение доблестных подвигов, вершимых с помощью РНС, Андрею Карпати в замечательной статье из его блога “Непостижимая эффективность рекуррентных нейронных сетей”. Их способности действительно ошеломляют.
Существенную роль в этих успехах играет использование LSTM, особого вида рекуррентных нейронных сетей. Для многих задач они подходят намного лучше, чем стандартная версия. Почти все потрясающие результаты, основанные на рекуррентных нейронных сетях, получены благодаря этой их разновидности. Именно LSTM мы и рассмотрим в этом очерке.
Проблема долгосрочных зависимостей
Одна из идей, которая делает РНС столь притягательными, состоит в том, что они могли бы использовать полученную в прошлом информацию для текущих задач. Например, они могли бы использовать предыдущие кадры видео для понимания последующих. Если бы РНС могли это делать, они были бы крайне полезны. Но могут ли они? Зависит от ситуации.
Иногда нам достаточно недавней информации, чтобы выполнять текущую задачу. Например, представим модель языка, которая пытается предсказать следующее слово, основываясь на предыдущих. Если мы пытаемся предсказать последнее слово в предложении “Тучи на небе”, нам не нужен больше никакой контекст - достаточно очевидно, что в конце предложения речь идёт о небе. В таких случаях, где невелик промежуток между необходимой информацией и местом, где она нужна, РНС могут научиться использовать информацию, полученную ранее.
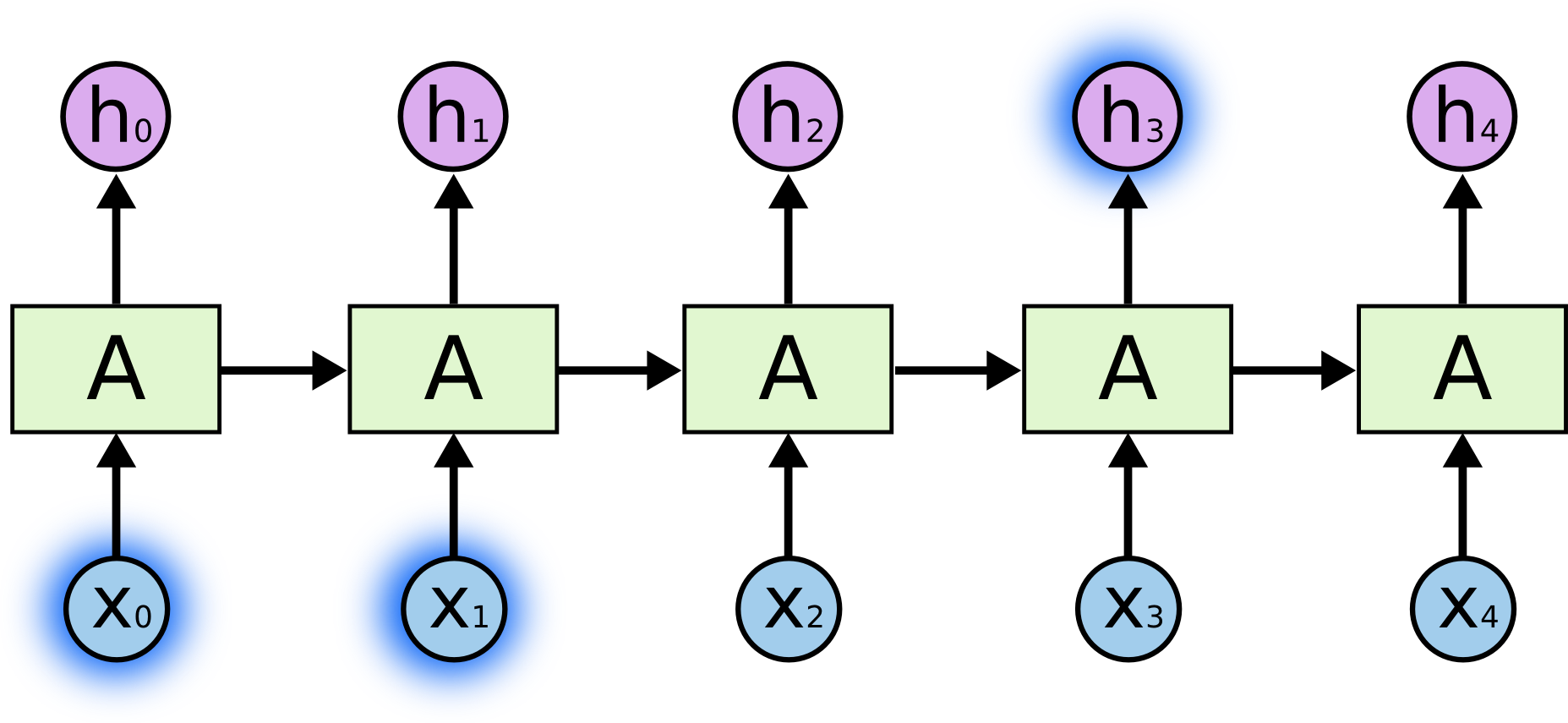
Но также бывают случаи, когда нам нужен более широкий контекст. Предположим, нужно предсказать последнее слово в тексте “Я вырос во Франции… Я свободно говорю по французски”. Недавняя информация подсказывает, что следующее слово, вероятно, название языка, но если мы хотим уточнить, какого именно, нам нужен предыдущий контекст вплоть до информации о Франции. Совсем не редко промежуток между необходимой информацией и местом, где она нужна, становится очень большим.
К сожалению, по мере роста промежутка, РНС становятся неспособны научиться соединять информацию.
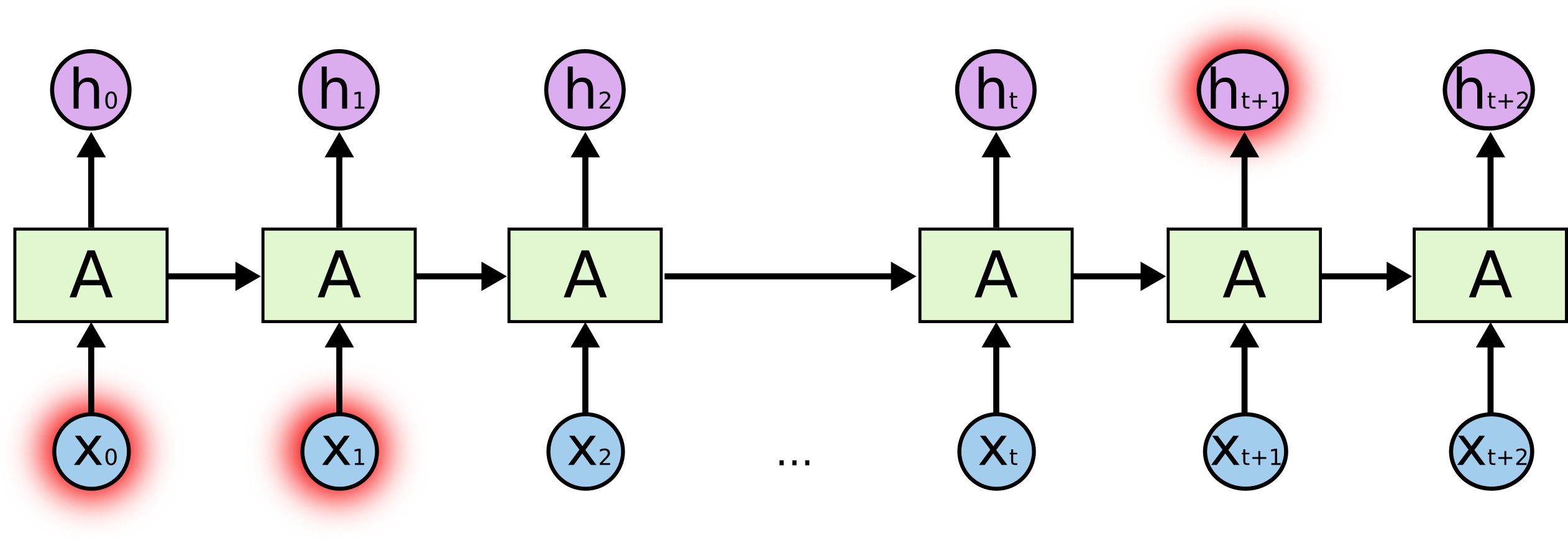
Теоретически, РНС способны обрабатывать такие долговременные зависимости. Человек может тщательно подобрать их параметры, чтобы решать игрушечные проблемы такой формы. К несчастью, на практике, непохоже, чтобы РНС были способны выучить такое. Проблема была глубоко изучена Хохрейтером (Hochreiter) (1991) [немецкий] и Бенджио и др. (1994). Им удалось найти некоторые достаточно фундаментальные причины, почему это может быть трудно.
К счастью, LSTM не имеют этой проблемы!
LSTM сети
Сети долго-краткосрочной памяти (Long Short Term Memory) - обычно просто называют “LSTM” - особый вид РНС, способных к обучению долгосрочным зависимостям. Они были предложены Хохрейтером и Шмидхубером (Schmidhuber) (1997) и доработаны и популяризованы другими в последующей работе1. Они работают невероятно хорошо на большом разнообразии проблем и в данный момент широко применяются.
LSTM специально спроектированы таким образом, чтобы избежать проблемы долгосрочных зависимостей. Запоминать информацию на длительный период времени - это практически их поведение по-умолчанию, а не что-то такое, что они только пытаются сделать.
Все рекуррентные нейронные сети имеют форму цепи повторяющих модулей (repeating module) нейронной сети. В стандартной РНС эти повторяющие модули будут иметь очень простую структуру, например, всего один слой гиперболического тангенса (\(\tanh\)).
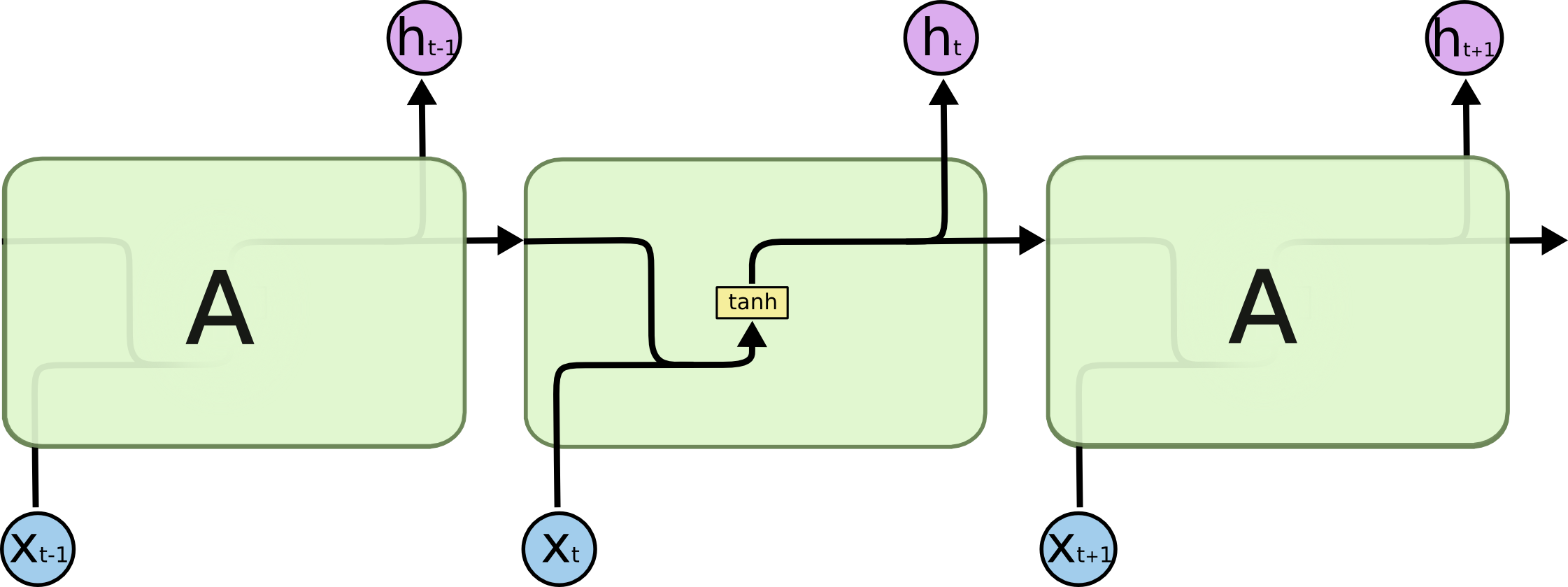
Повторяющий модуль в стандартной РНС содержит один слой.
LSTM тоже имеют такую цепную структуру, но повторяющий модуль имеет другое строение. Вместо одного нейронного слоя их четыре, причем они взаимодействуют особым образом.
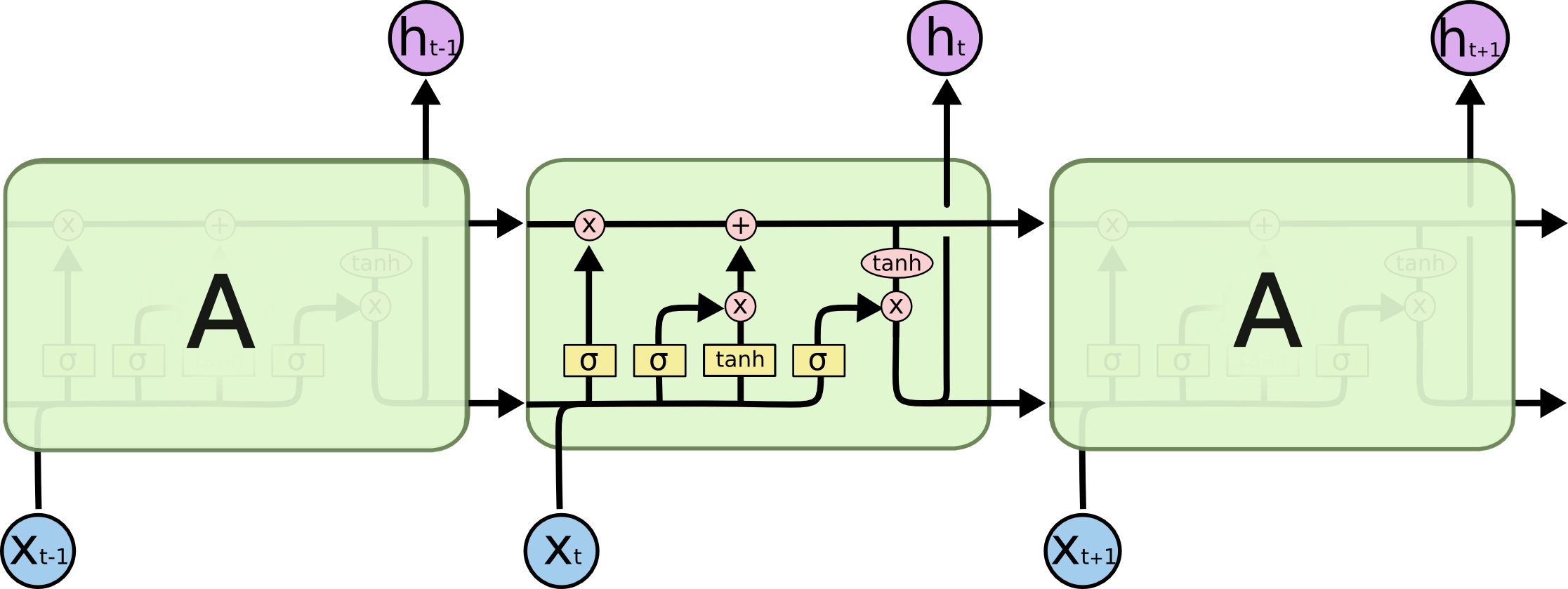
Повторяющий модуль в LSTM содержит четыре взаимодействующих слоя.
Не переживайте, если вы не понимаете деталей того, что происходит. Мы пройдем по диаграмме LSTM шаг за шагом позже. Пока что просто попробуйте привыкнуть к обозначениям, которые мы будем использовать.

В диаграмме выше каждая линия передает целый вектор от выхода одного узла к входам других. Розовые круги представляют поточечные операторы, такие как сложение векторов, в то время, как желтые прямоугольники - это обученные слои нейронной сети. Сливающиеся линии обозначают конкатенацию, в то время как ветвящиеся линии обозначают, что их содержимое копируется, и копии отправляются в разные места.
Главная идея LSTM
Ключ к LSTM - клеточное состояние (cell state) - горизонтальная линия, проходящая сквозь верхнюю часть диаграммы.
Клеточное состояние - это что-то типа ленты конвейера. Она движется прямо вдоль всей цепи только лишь с небольшими линейными взаимодействиями. Информация может просто течь по ней без изменений.
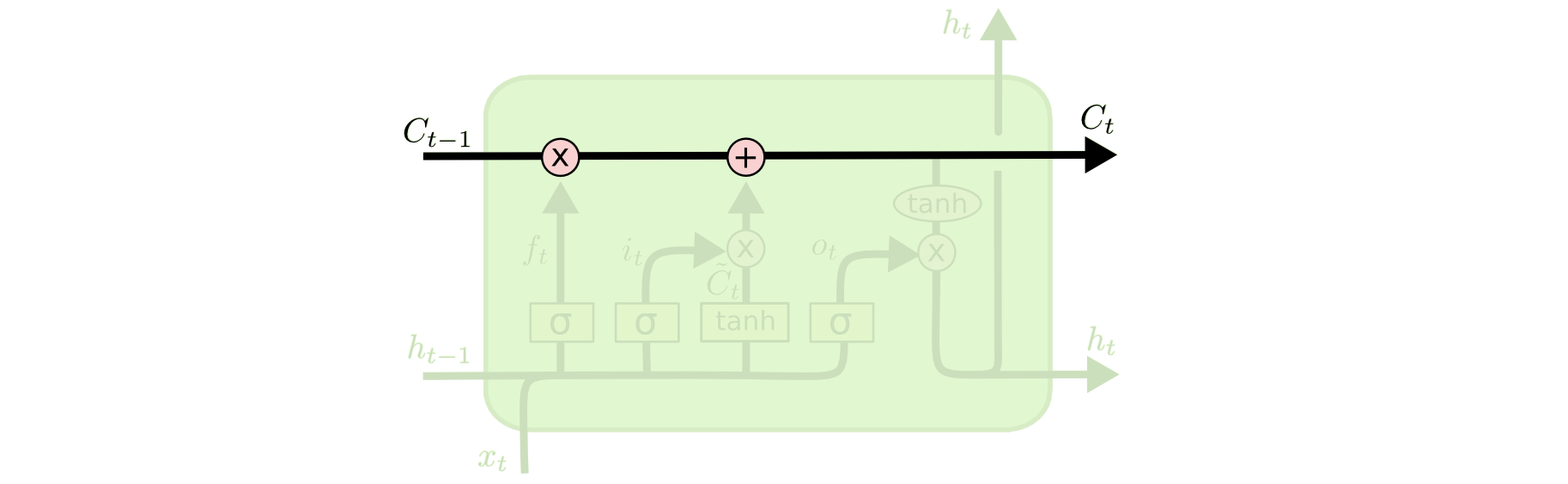
LSTM имеет способность удалять или добавлять информацию к клеточному состоянию, однако эта способность тщательно регулируется структурами, называемыми вентилями (gates).
Вентили - это способ избирательно пропускать информацию. Они составлены из сигмоидного слоя НС и операции поточечного умножения (pointwise multiplication).
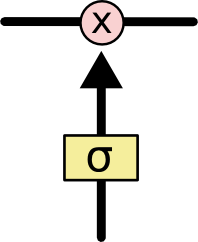
Сигмоидный слой подает на выход числа между нулем и единицей, описывая таким образом, насколько каждый компонент должен быть пропущен сквозь вентиль. Ноль - “ничего не пропускать”, один - “пропускать все”.
LSTM имеет три таких вентиля, чтобы защищать и контролировать клеточное состояние.
Пошаговый разбор LSTM
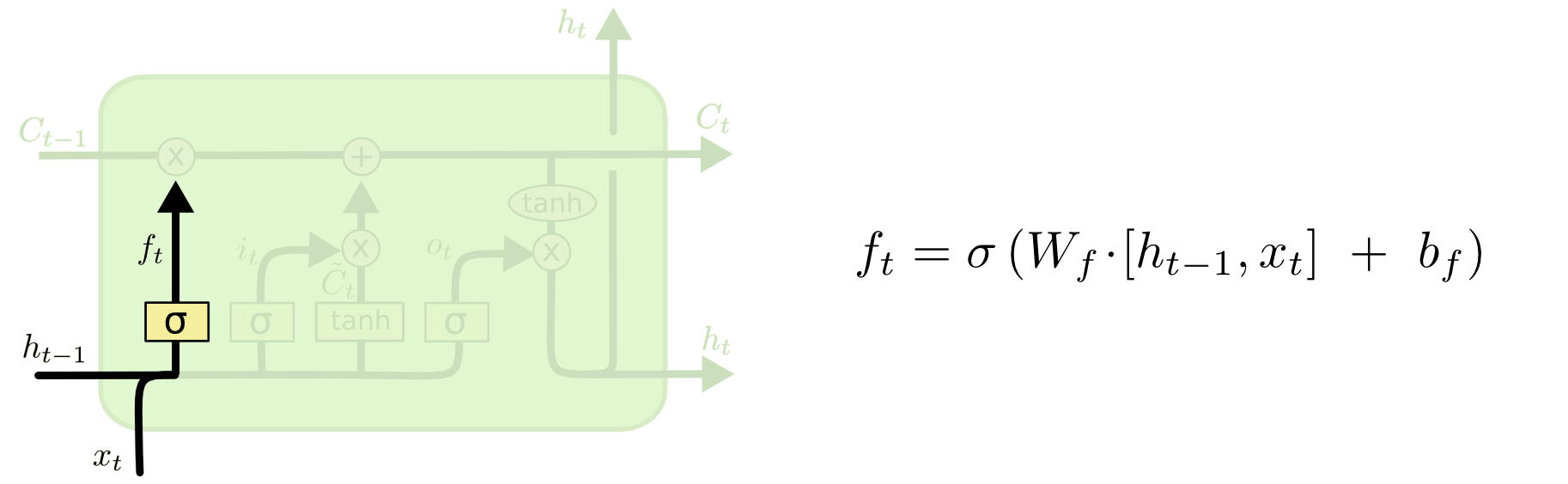
Первым шагом в нашей LSTM будет решить какую информацию мы собираемся выбросить из клеточного состояния. Это решение принимается сигмоидным слоем, называемым “забывающим вентилем” (“forget gate layer”). Он смотрит на \(h_{t-1}\) и \(x_t\) и подает на выход число между \(0\) и \(1\) для каждого числа в клеточном состоянии \(C_{t-1}\). Единица означает “сохрани это полностью”, в тот время как ноль означает “избавься от этого полностью”.
Давайте вернемся к нашему примеру языковой модели, пытающейся предсказать следующее слово, основываясь на всех предыдущих. В такой проблеме клеточное состояние может включать род подлежащего, что позволит использовать правильные формы местоимений. Когда мы видим новое подлежащее, мы забываем род предыдущего подлежащего.
Следующим шагом будет решить, какую новую информацию мы собираемся сохранить в клеточном состоянии. Этот шаг состоит из двух частей. Во-первых, сигмоидный слой, называемый “входным вентилем” (“input gate layer”), решает, какие значения мы обновим. Далее, слой гирпеболического тангенса создает вектор кандидатов на новые значения \(\tilde{C}_t\), который может быть добавлен к состоянию. На следующем шаге мы соединим эти две части, чтобы создать обновление для состояния.
В примере с нашей языковой моделью мы бы хотели добавить род нового подлежащего к клеточному состоянию, чтобы заменить род старого, которое мы должны забыть.
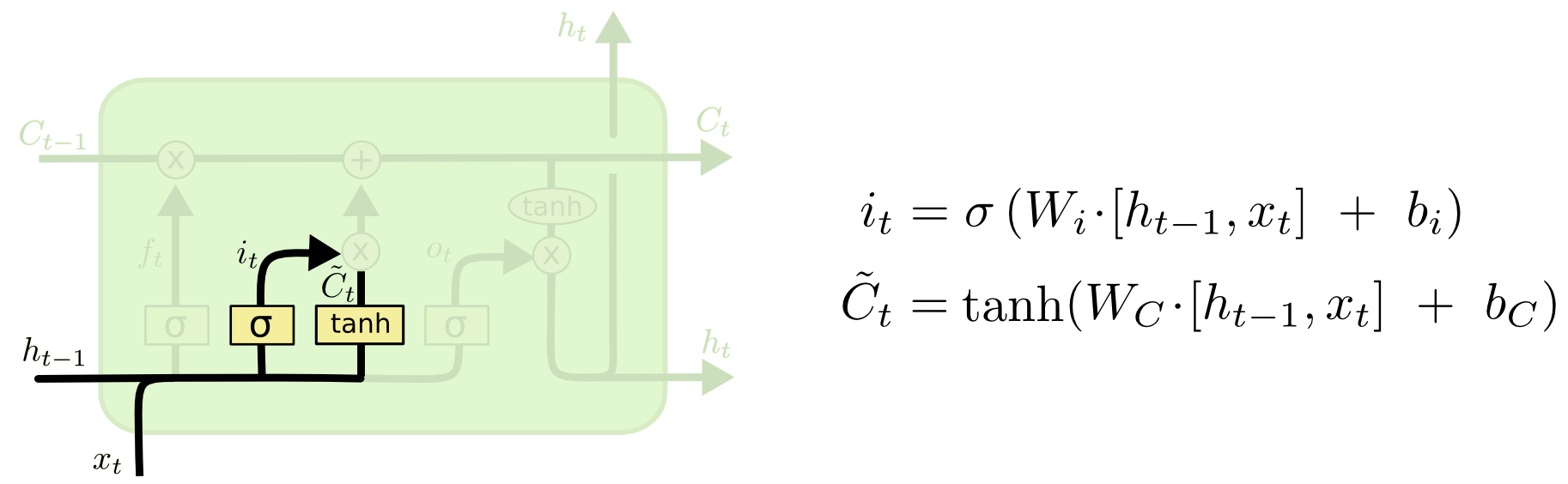
Теперь пришла пора обновить старое клеточное состояние, \(C_{t-1}\), новым клеточным состоянием \(C_t\). Все решения уже приняты на предыдущих шагах, осталось только сделать это. Мы умножаем старое состояние на \(f_t\), забывая все, что мы ранее решили забыть. Далее мы прибавляем \(i_t*\tilde{C}_t\). Это новые кандидаты в значения, масштабированные в соответствии с тем, как сильно мы решили обновить каждое значение состояния.
В случае с языковой моделью, это как раз то место, где мы теряем информацию о роде старого подлежащего и добавляем новую информацию, как решили на предыдущих шагах.
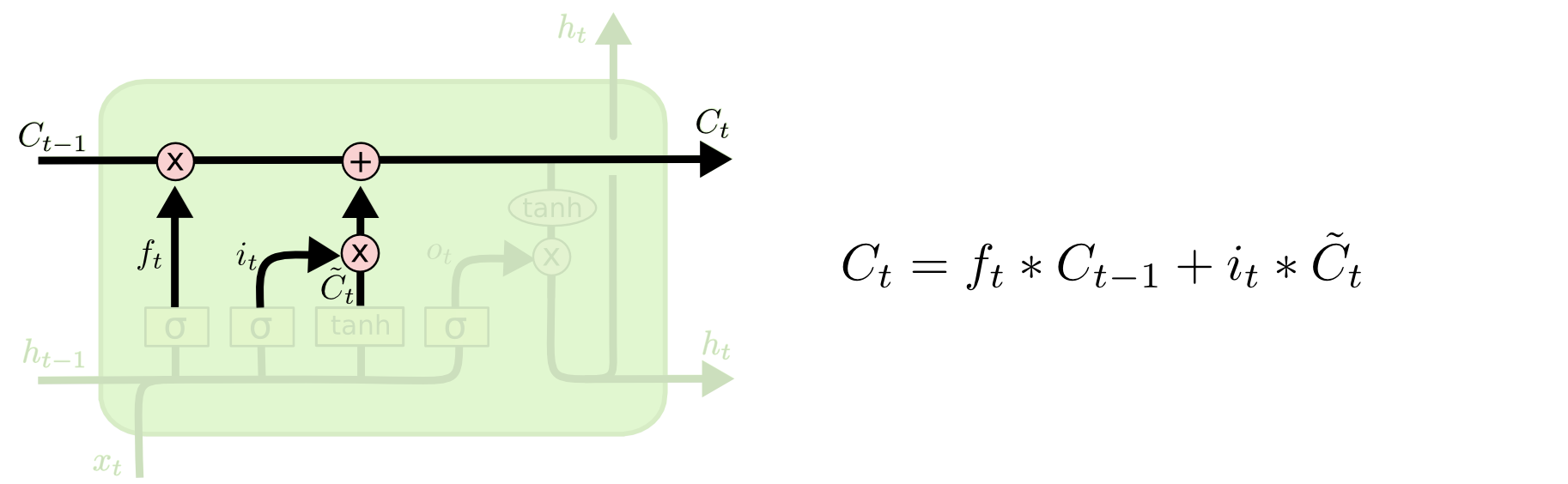
Наконец, нам нужно решить, какой результат мы собираемся подать на выход. Этот результат будет основан на нашем клеточном состоянии, но будет его отфильтрованной версией. Сначала мы запускаем сигмоидный слой, который решает, какие части клеточного состояния мы собираемся отправить на выход. Затем мы пропускаем клеточное состояние сквозь гиперболический тангенс (\(\tanh\)) (чтобы уместить значения в промежуток от \(-1\) до \(1\)) и умножаем его на выход сигмоидного вентиля, так что мы отправляем на выход только те части, которые мы хотим.
В примере с языковой моделью, если она только что видела подлежащее, она могла бы подать на выход информацию, относящуюся к глаголу (в случае, если следующее слово именно глагол). К примеру, она, возможно, подаст на выход число подлежащего (единственное или множественное). Таким образом, мы будем знать, какая форма глагола должна быть подставлена (если конечно дальше идет именно глагол).
Варианты долго-кратковременной памяти
До сего момента я описывал достаточно обычную LSTM. Но не все LSTM именно такие, как описано выше. На самом деле, похоже, почти каждая публикация, включающая LSTM использует немного другую версию. Отличия невелики, однако некоторые из них стоит упомянуть.
Один из популярных вариантов LSTM, предложенный Герсом и Шмидгубером (Gers & Schmidhuber) в 2000 добавляет “глазковые соединения” (“peephole connections”). Это значит, что мы позволяем вентилям “подглядывать” за клеточным состоянием.
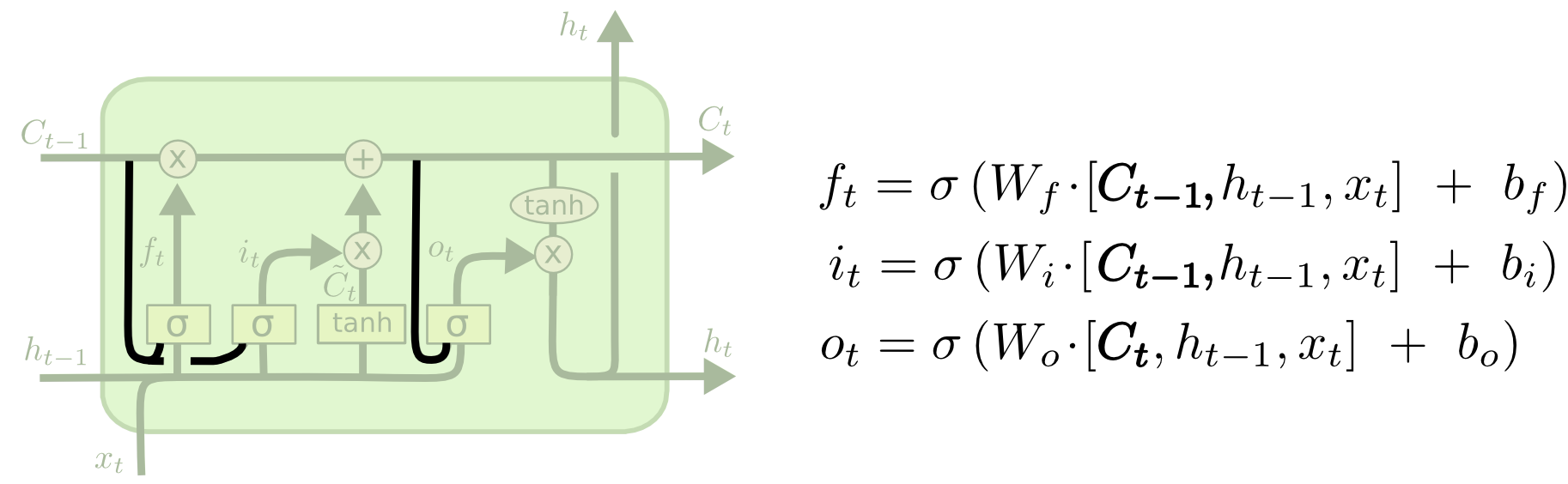
Диаграмма выше добавляет глазки (смотровые отверстия) для всех вентилей, но во многих публикациях вы встретите лишь некоторые из них, а не все сразу.
Другая вариация - использование спаренных забывающих и входных вентилей. Вместо того, чтобы независимо решать что забыть и куда мы должны добавить новую информацию, мы принимаем эти решения одновременно. Мы забываем что-то только в том случае, когда мы получаем что-то другое на это место. Мы получаем на вход новые значения только когда забываем что-то старое.
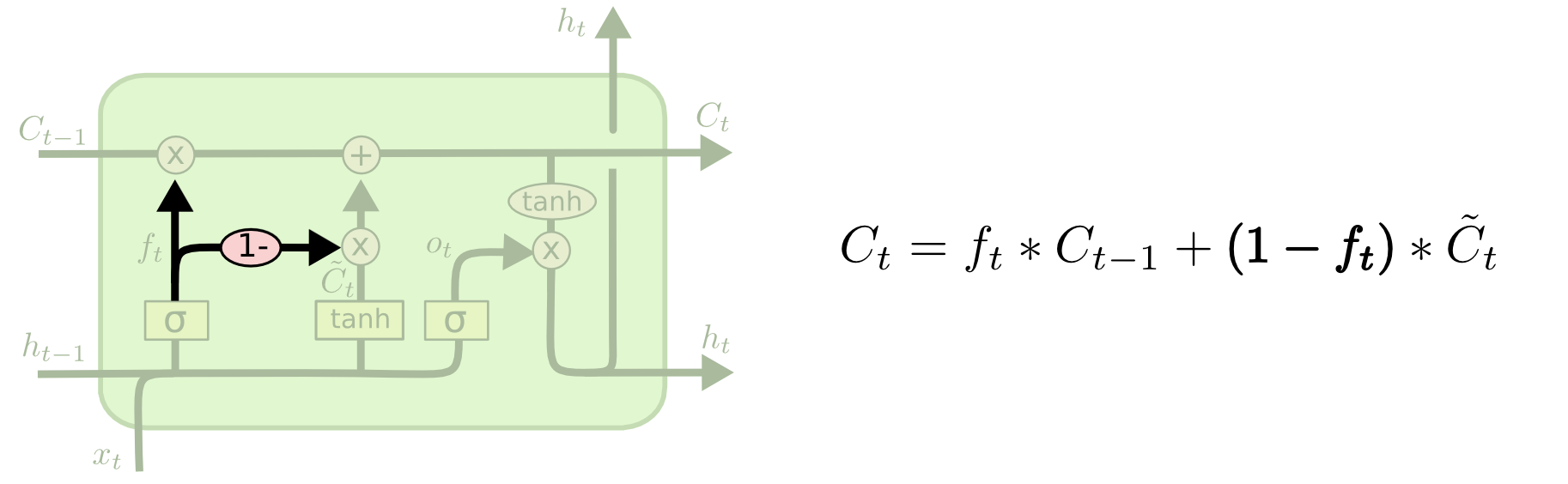
Несколько более существенно отличается от LSTM вентильная рекуррентная единица (Gated Recurrent Unit) или GRU, предложенная Чо (Cho) и др в 2014. Она совмещает забывающие и входные вентили в один “обновляющий вентиль” (“update gate”). Она также сливает клеточное состояние со скрытым слоем и вносит некоторые другие изменения. Модель, получающаяся в результате, проще, чем обычная модель LSTM и она набирает популярность.

Это только некоторые из наиболее заметных вариантов LSTM. Есть множество других, например глубинно-вентильные РНС (Depth Gated RNNs) Яо (Yao) и др. (2015). Существует и совершенно другой подход к изучению долговременных зависимостей, например часовые РНС (Clockwork RNNs) Коутника (Koutnik) и др. (2014).
Какой из этих вариантов лучший? Имеют ли эти различия какое-то значение? Грефф (Greff) и др. (2015) сделали замечательное сравнение популярных вариантов и обнаружили, что они все примерно одинаковы. Джозефович (Jozefowicz) и др. (2015) протестировали более тысячи архитектур РНС и обнаружили, что некоторые из них работают лучше, чем LSTM на определенных задачах.
Заключение
Ранее я упомянул примечательные результаты, полученные с помощью РНС. По-сути, все это достигнуто с помощью LSTM. Они действительно работают намного лучше для многих задач!
Записанные как набор уравнений LSTM выглядят достаточно пугающе. Надеюсь, это пошаговое разъяснение сделало их немного более доступными.
LSTM были большим шагом к новым возможностям РНС. Естественно задаться вопросом, будет ли следующий большой шаг. Среди исследователей распространено мнение, что следующий шаг есть, и это - внимание (attention). Идея состоит в том, чтобы позволить каждому шагу РНС выбирать информацию для просмотра из некого большего ее объема. Например, если вы используете РНС, чтобы создать описания к картинкам, они могли бы выбирать только часть картинки, на которую смотреть, для каждого слова в получающемся описании. Собственно, именно это сделали Ксу (Xu) и др. (2015), и это может стать неплохой отправной точкой, если вы захотите исследовать внимание! Уже есть некоторое число впечатляющих результатов использования внимания, и похоже, что не за горами еще больше…
Внимание - не единственное замечательное направление в исследованиях РНС. Например, сетчатые LSTM (Grid LSTMs) Кальхбреннера (Kalchbrenner) и др. (2015) выглядят крайне многообещающе. Работы, использующие РНС в порождающих моделях (generative models) - такие, как Грегор (Gregor) и др. (2015), Чун (Chung) и др. (2015) или Байер (Bayer) и Озендорфер (Osendorfer) (2015) - также кажутся интересными. Последние несколько лет были замечательным временем для рекуррентных нейронных сетей, и грядущие годы сулят быть еще более замечательными.
Благодарности
Я благодарен многим людям, которые помогли мне лучше понять LSTM, а также за комментарии к картинкам и отзывы на статью.
Я признателен моим коллегам из Google за ценные отзывы, особенно Oriol Vinyals, Greg Corrado, Jon Shlens, Luke Vilnis и Ilya Sutskever. Я также благодарен многим другим друзьям и колегам за то, что они уделяли время, чтобы помочь мне, включая Dario Amodei и Jacob Steinhardt. Особенно я благодарен Kyunghyun Cho за крайне вдумчивую переписку насчет моих диаграмм.
До этого поста я попрактиковался в объяснении LSTM во время двух серий семинаров, где я преподавал нейронные сети. Спасибо всем, кто принял участие в тех семинарах за их терпение ко мне, а также за отзывы.
Примечания
1 Кроме изначальных авторов множество людей внесло свой вклад в современные LSTM. Вот далеко не полный список: Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustian Gomez, Matteo Gagliolo, and Alex Graves